PC-ORD
Windows 生态数据的多变量分析专业软件
PC-ORD 对电子表格中输入的生态数据进行多变量分析。我们的重点是用于分析社区数据的非参数工具、图形表示、随机化测试和自举置信区间。除了用于转换数据和管理文件的实用程序外,PC-ORD 还提供了许多主要统计软件包中没有的排序和分类技术,包括:CCA、DCA、指标物种分析、Mantel 测试和部分 Mantel 测试、MRPP、PCoA、perMANOVA、RDA 、双向聚类、TWINSPAN、Beals 平滑、多样性指数、物种列表、许多排序叠加方法(定量、符号编码、颜色编码、网格、联合图、双图、连续向量)、各种旋转方法、3-D排序图形,Bray-Curtis排序,城市街区距离测量,物种面积曲线,树数据摘要、出版质量树状图和自动驾驶模式非度量多维缩放(NMS 或 NMDS)。可以分析非常大的数据集。大多数操作接受最多 32,000 行或 32,000 列和最多 536,848,900 个矩阵元素的矩阵,前提是您的计算机中有足够的内存。该术语是为生态学家量身定制的。完整的手册包含在上下文相关的帮助系统中。
永久许可证
许可证是永久的(不需要年费或更新费)。
离线使用
该软件是单机的(可以在没有互联网连接的情况下使用)。
数字交付
软件以下载方式交付;除非订购书籍,否则不会有发货。
立即获取 PC-ORD
立即购买核心功能
顾问向导
通过问答对话,PC-ORD 使用决策树来帮助您决定如何转换和分析数据。您也可以将其用作自学工具。社区分析决策树海报现已发布。
图形功能
可以打印出版质量的图形、保存到文件或粘贴到其他应用程序中。可以使用各种叠加,包括不同的符号大小、标签、矢量、网格和联合图。数据中的代码组按颜色或符号类型。
图表类型
基础图表
- 联合图 2D
- 定量叠加
- 基本协调 2D
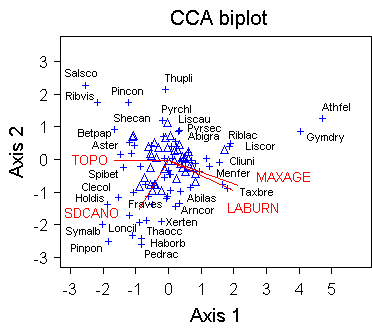
- CCA biplot
- 基本协调 3D
- 联合绘图 3D
高级图表
- 丛覆盖
- 凸壳填充多边形
- 山顶地块
- 轮廓叠加
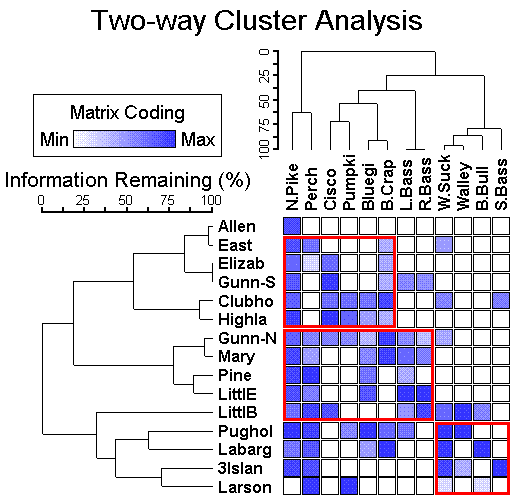
- 聚类分析
- 双向聚类树状图
专业图表
- 有序主矩阵
- 连续向量
- 翻译为原点
- NMS 迭代压力
- 物种面积曲线
- NMS 屏幕图
图形格式
- 反射/旋转坐标
- 覆盖侧图拟合信封
- 物种面积曲线的置信带
- PCA 双标图向量
- 保存为 emf、wmf、bmp、jpeg、gif 和 tiff
- 32 种符号类型或颜色
- 自定义图形分辨率
- 灵活的刻度线放置
- 象限敏感标记
- 可选箭头和大小
- 高斯核平滑器
排序方法
Bray-Curtis (Polar)
在 Bray 和 Curtis 的原始方法之外,我们提供了许多选项和改进,例如垂直轴和方差回归端点选择。
典型对应分析 (CCA)
CCA 在 PC-ORD 中的排序方法中是独一无二的,因为主矩阵的排序(通过倒数平均)受到第二矩阵中包含的变量的多元回归的约束。在群落生态学中,这意味着样本和物种的排序受到它们与环境变量的关系的限制。
去趋势对应分析(DCA,DECORANA)
DCA 是一种基于倒数平均的特征分析排序技术(RA;Hill 1973)。DCA 面向生态数据集,术语基于样本和物种。DCA 同时协调物种和样品。
非度量多维缩放 (NMS)
非度量多维缩放(NMS、MDS、NMDS 或 NMMDS)是一种排序方法,非常适合非正态或任意、不连续或其他有问题的比例的数据。NMS 通常是社区数据的最佳排序方法。我们的自动驾驶功能使其易于使用。包括蒙特卡洛显着性检验。
NMS 分数
NMS 分数为非度量多维缩放 (NMS) 提供了一种预测算法。这不是预测意义上的预测,而是与使用多元回归估计因变量相同的统计预测。NMS 分数根据先前的排序计算新项目的分数。
主成分分析 (PCA)
主成分分析是基本的特征分析技术。它使每个连续轴解释的方差最大化。尽管它对许多社区数据集有严重的错误,但当数据集接近多元正态性时,它可能是最好的技术。
主坐标分析 (PCoA)
主坐标分析是一种类似于 PCA 的特征分析技术,不同之处在于它从样本单元(行)之间的距离矩阵中提取特征向量,而不是从相关或协方差矩阵中提取特征向量。
倒数平均 (RA) = 对应分析 (CA)
倒数平均也称为对应分析 (CA)。它通过在改编自康奈尔生态计划系列的 DCA 程序中选择选项在 PC-ORD 中执行。倒数平均 (RA) 自动产生正常和转置排序。
冗余分析 (RDA)
冗余分析基于线性模型将一组响应变量建模为一组预测变量的函数。因此,RDA 适用于与规范对应分析 (CCA) 相同的概念问题。
加权平均
最简单但通常有效的排序方法是加权平均。基本操作是相同的:一组预先分配的物种权重(或物种组的权重)用于计算站点(样本单位)的分数。
模糊集 (FSO)
模糊集排序将模糊集理论应用于生态排序中的直接梯度分析。这种排序方法要求用户假设物种群落与环境变量或其他预测变量之间的关系。
比较分数(Compare Ordinations)
评估两个排序的相似性,独立于任何旋转、反射、轴单位和维度数。这是通过评估两个排序的点间距离之间的相关性来实现的。